Projects
Web Development
Technology
September 1, 2025
Making Data Beautiful: Building Greenhub’s End-to-End Architecture
From an Idea to Full SaaS; End-to-End development on a Statewide scale. How I built the architecture for Greenhub and made finding information easier for thousands of people.

Steven
Software Engineer
Preface and Overview
Building Greenhub has been the most fulfilling project that I have had the pleasure of working to date. It was not only the most complete and complex, but it has had the most impact. Not only in usefulness for its users, but for me too.
This project has made me realize that I love working with data, specifically the process of finding, collecting, organizing, cleaning, and presenting data and information in intuitive interfaces and datasets. After Greenhub was published, I decided to focus on and specialize in ETL Pipelines and data engineering as my "T" skill along with Full-stack web and app development.
This article will go in depth to my thoughts and decision making processes while I was working on Greenhub. You can visit the platform by clicking on this link:
Greenhub - Live Site
Scope & Responsibilities
- Designed and deployed a multi-source data ingestion and normalization pipeline capable of handling 120k+ records daily
- Built a responsive web application supporting fast search, sorting, and filtering at scale
- Implemented secure authentication and account features, including saved lists and price-drop/restock notifications
- Managed deployment, server configuration, and security for 99.9% uptime
Impact
- Performance: Average search set (5k+ products) loads initial render in ~1 second; filters/sorts execute in <1 second
- Adoption: 1,500+ unique users in the first month; sustaining ~150 daily actives with 5–7 min avg. sessions
- Reliability: 99.9% uptime since launch; architecture ready for 10× growth in capacity and usage
Accomplishments
- Architected statewide product aggregation from disparate sources into a unified, query-optimized database
- Delivered near instant user interactions even on dataset sizes exceeding typical consumer search apps
- Designed a system that is maintainable, secure, and extensible for future market expansions
Jump to Section:
- 1. 💬 The Talks (Beginning the Project)
- 2.🚰 The Plumbing (Python + AI)
- 3. 🤔 Learning and LLMs
- 4. 💁♀️ Personal Experience
- 5. 🧬 The Blueprints (The Scrapers)
- 6. 🧶 The Wiring (Server Hardening and Database Config)
- 7. 🖼️ The Frame and Glue (Schemas + FastAPI)
- 8. 🎨 The Paint (Next.js)
- 9. 🪴 The Furnishings (Performance + Optimization)
- 10. 🔥📊 The Tools (Flame Charts + DevTools)
- 11. 🪵 The Maintenance (Logs + Monitoring)
- 12. 💅 The Adornments (UI/UX Design)
- 13. 🏡 Open House! (Adding User Accounts and Features)
- 14. ☀️ Summary
💬 The Talks (Beginning the Project)
I was recently given my first professional opportunity as a software engineer; a freelance project to make a data aggregator and price comparison tool for patients in Pennsylvania to find the cannabis they needed at the best prices available.
The concept was inspired by an existing community site, but it had seemed that the sole maintainer of the existing site had gotten busy with life and wasn't being updated or patched. My client wanted to create a similar service that was actively maintained with consistent vision and direction that expanded on the work done on the previous community tool.
The tool collects data from multiple sources and presents it all in one coherent interface. Collecting the information requires a technique called web scraping. I was already working on a game as a personal project at the time I was contacted for this request that would require me to know how to scrape the internet for data.
Without getting too lost in the details — the point is, I was already planning to learn web scraping when I was contacted about making this platform that required me to learn it. I informed my client honestly that I didn’t know anything about web scraping yet — but that I was interested and that I would look into it and get back to them.

Web Scraping is when a program requests and collects data from the internet.
When I started Greenhub I was very familiar with Next.js and its capacity for frontend file system page structure and its internal API route structure, as I have built projects with them before. I was also familiar with TypeScript and assertion of types and implementation of interfaces, classes, and OOP to control reliable data input and output for consistency and integrity.
Now though, I had to get more familiar with databases, data collection, data engineering, data hygiene, backend processes requiring API routing, security, and explicit configuration; and looking back, every bit of it was so much fun.
After about two and a half months, I shipped an end-to-end platform: a daily ETL pipeline ingesting 120,000+ products statewide; <4s initial render for a 25,000-product result set (largest available); sub-1s filter/sort at that scale; user accounts with saved lists; and price-drop/restock notifications—running on indexed columns and secured via environment-stored secrets, JSON Web Tokens (JWT), and bcrypt.
From here, when I describe new concepts or processes I will often use parens and braces to explain them or expand the acronym on first introduction if I feel it should be done for non-technical readers — or readers not familiar with the tech.

My daily monioring log for the scraper script to monitor my ETL Pipelines's health
🚰 The Plumbing (Python + AI)
I took the initiative before confirming the contract and started working with Python to build my first API scraper — which honestly was a pretty easy transition from JavaScript/TypeScript.
I already knew what I wanted to accomplish, the use edge cases of data structures and certain systems, and how to go about choosing what was needed, but I had to take some time to learn to fill in the gaps where syntactic knowledge was missing; specifically in the Python syntax.
Python’s syntax is straightforward and the execution context is determined by white-space indentation. To add a condition and action in a loop, you would write the loop declaration, enter + tab, write the condition, enter + tab, write the action.
Then I just had to do a bit of research, find the libraries I needed, learn how to use pip (the package installer for Python, like npm for JavaScript), and how to use the virtual environment correctly (basically a dedicated workspace for a project so not all installs are globally installed).
Those were the biggest learning curves when learning Python coming from JavaScript TypeScript bracket-land, and even then while stumbling around with a new language, syntax, and writing style, it’s fast and easy to correct with a simple “what did I do wrong here” prompt with GPT.

I’m on a budget here and I’m relying on GPT to make these images that don’t add whitespace to the Python scripts and misspell JavaScript - which is a perfect segue to my next section...
🤔 Learning and LLMs
Indulge me for a tangent — in my humble opinion, AI is best used for the amplification of existing functional capacities or the outright automation of the same capacities or ones that do not exist. I believe the former is where AI is best used for people who want to learn. AI can dramatically amplify the capacity to learn, especially with deeply complex systems.
If you have a good idea of what you want to accomplish and how a system that achieves that goal should or could work — how each modular system composes it, and how each system should fit together to create a larger system — then if you ever get stuck writing the code, you always have the fallback of asking an AI for syntax or just ask an AI IDE to build it outright.
You — the human — remain the architect of the systems while using modern tools to help navigate and conquer unfamiliar problems that you have not been introduced to yet. Integrating AI into your workflow this way allows for you to build faster and learn faster on a broader spectrum compared to doing raw deep dives into documentation for hours or days at a time.
I’m not implying that reading the docs, learning the fundamentals, or doing deep dives and falling down rabbit holes doesn't help you learn about one to a few things really well — read the docs, get lost in afternoon research, etc. — but I am saying that using AI to explain them contextually in at least a conversational style makes understanding new and abstract concepts far more effective than the docs alone; especially if learning quickly is a priority.

If I am reading the docs and have a question about them — AI can either answer it directly, or give me at least some relevant information that helps me fill in the know-how I needed to complete the task. Applying new knowledge will always be the best way to learn, and there are lessons to be learned in getting things wrong over and over again before getting it right — but I again would argue that time is a cost.
The job market and skill demand in tech is simply not the same as it was 10, 5, or even 3 years ago. Adapting and learning quickly are skills, and they are very much in demand. I mentioned before that AI is excellent for amplification AND automation, so let me be clear — AI should not be used to automate thinking when you want to learn. It should amplify efficiency and effectiveness while being a pair partner, pseudo-senior mentor, and/or a building/learning tool.
To be direct — if you use an AI IDE to create code or an entire project without knowing how the system works, writing guiding docs or taking any measures beyond the prompt to guide the AI IDE, and can not fix breaks or bugs in the code that it generates, that is what’s now known as “vibe coding.” The way I described it previously with conversation with an LLM as an amplifier is like a supercharged Google search/syntax cipher that you can talk to with contextual relevance. There is also code/project generation with AI IDEs, and all three of these are entirely different approaches to using AI in workflows.
“Vibe coding” is when AI IDEs are used as pure automation without thinking about the project's internals or structure, which produces black-box projects that developers can’t maintain and don't truly understand. The danger isn’t the tool itself, it’s skipping the responsibility to learn and review.
Security in particular is a huge liability for these projects, and poor security practices are how we end up with data leaks of user info like what happened with the Tea dating platform. User data, direct messages, and even private images including government IDs for verification were leaked — one of the worst outcomes for users and for a developer’s reputation.
While it’s been reported that ‘lax coding practices’ contributed to the Tea data leak, there been only rumors that the project was built in the “Vibe coding” fashion.
The point however stands, if you entirely automate your platform and projects without the proper foundations and checks, there will be holes that attackers will find, memory will leak from, and bugs will permeate through.

💁♀️ Personal Experience
I personally have chosen to not use AI IDEs to automate work for me yet. I will explore it soon, but I'm very curious how effectively use one while still learning. It will have to be through reading a lot of generated code, reasoning about the logic, and making changes where appropriate.
I’ve thought about it quite a bit, and I don't think I would recommend them for people who are just starting to learn and want to know how every piece fits together. Like I said earlier, one of the best ways to learn is by applying the knowledge you gave gained. I’m still doing a lot of learning, and I don’t want to dilute any of it through extensive automation. Simultaneously, learning how to effectively integrate AI IDEs and LLMs into a workflow is an extremely in-demand skill.
I firmly believe that learning the fundamentals are essential before building anything meaningful — but also that learning and implementing them can be done faster with AI assistance; it's all a balance that requires some critical thought and sound judgement. I’m not saying “my way is the right way” — we’re all still learning how to use AI responsibly and effectively and there is more than one way to do that. But I am saying don't use AI to automate 100% of your work without understanding its output. The line between amplifier and automation could be the line between growing your skills and outsourcing your judgment.
All of that being said, refusing to use AI these days is comparable to insisting on doing math and writing competitively with a paper and pencil when everyone else is using Microsoft Office with spell check, autocomplete, built-in calculators, etc. It’s a new but necessary tool that defines how software engineering and many other professions are done forever — and it’s not going away.
I could even argue that only highly qualified specialists don’t need to use AI in their work — even then, they probably get the most use out of it. With know-how in best security practices, performance optimization, coding guidelines, and thoroughly documented architectural plans in project files, they are almost certainly the ones best suited for mass generating code using AI IDEs. At the very least, builders who have an excellent grasp on these concepts or amazing attention to detail and boundless curiosity should work well with them too. It requires reviewing a lot of code, code that that sometimes might not be that great. So you should know how to spot when something needs changed from the output of the model.
Anyway, I know this is a thoroughly debated area of discussion, and I’m always refining my assumptions and assertions — but for now, this is where I stand. AI is here to stay, so it’s worth talking about.

🧬 The Blueprints (The Scrapers)
With that rant out of the way, back to researching web scraping. Building my first script, I had to decide which method of scraping worked best for my case. I learned there are three main ways to collect data from the internet via scraping;
- HTML scanning and matching with tools like Beautiful Soup
- Headless browsers like Selenium and Playwright
- API calls — which is generally considered to be the most reliable.
“Reliable” is maybe not the best word to use, because the nature of scraping isn’t often able to provide consistently reliable streams of data over long periods of time — but relative to the other options it is the most stable.
API calls don’t depend on the elements of a page, they pull data from a server — so as long as the shape of the data doesn’t change, the script will work. APIs, frontend displays, and HTML especially do change over time though; which means scraper scripts need to be monitored regularly and updated often and usually reactively.
I chose to consume publicly available JSON endpoints because it was the cleanest (compared to messy and inconsistent HTML parsing), fastest (compared to headless browsers), and the easiest to set up (if you already work with APIs) and to maintain when changes needed to be made. The first step was to identify publicly available, structured data sources and build provider-specific extractors.

It’s important to note — data collection on publicly available endpoints can be lawful when done within reason and consideration. To collect data ethically and legally, you should be respectful of the amount of data that you collect in a short amount of time. Some “white-hat” guidelines to keep in mind when when Robin-Hooding your data responsibly are:
- Be gentle to vendor systems
- Don’t effectively DDoS them with data requests
- Absolutely avoid paywalled content or content that requires a login to view.
Scraping paid content is a quick way to get blocked, fined, or charged.
Scraping requires a bit of attention and finesse; all APIs are built differently and require their own companion scraper with various header requests and payload structures. In my case, some providers hid terpene data behind per-product endpoints or hydrate it client-side, so they need solutions like on-demand data fetching or headless browser utilization.
Platforms also model and name product data differently — some treat a different weight of a product as an entirely different product with a new ID, others treat it as a variant of that product and have long lists of weights available. I had to write multiple provider-specific scripts to accommodate these checks and quirks — and most importantly — normalize them into one unified schema in my database for direct comparison on my frontend.
Normalizing data is a natural second step to taking raw data and aggregating it for comparison to other platforms. For example with Greenhub — we’ll use the example of the weights mentioned above. Some say that one gram worth of product is “one gram”, others say “1g”, others “1 gram”, etc. In Greenhub’s case, I built normalizers for almost all fields for all vendors to ensure that all data was filterable and sortable by common metrics. This is what’s called an ETL Pipeline — Extract, Transform, and Load. You collect data, normalize it, store it, and finally load it for viewing — either in a terminal or a custom UI.
⚠️ Disclaimer: I’m not a lawyer. This isn’t legal advice, advocacy, or encouragement to scrape. It’s purely informational — do your own research and understand the risks before building software like this.

There is a fine line between collecting and stealing data. Do your research and know the difference!
Once a scraper script was working for a platform, I determined what uniquely identified each of the contributors to the platform and used “stores” in Python as injectable data to “dynamicize” (a word that I just made up to describe converting something of a static nature to a dynamic nature) the requests.
Stores are kind of like props in React which allow for you to pass data from a parent component to a child component; but the components here are scripts. This meant I could pass unique contributor info into the requests ran from the script, and everything worked seamlessly because they all adhered to the same API structure.
To be transparent; I am intentionally being vague on the internals of how the scraper works and with what platforms I am referencing — simply because I want them to continue working; I don’t want them copied or countered.
I will continue lightly brushing over the project’s internals throughout the rest of the article for similar reasons; stability and security. However, I would be happy to discuss them further anytime to anyone who is interested.
If you’re interested, send a message through our contact form or directly to me on LinkedIn and lets set something up!
🧶 The Wiring (Server Hardening and Database Config)
Right, so I have my data and my multiple scraper scripts to collect it all from each platform. Now I needed to make a database to store it all and a frontend to render and interact with it. I chose to use SQLite in earlier iterations of the platform for simplicity, but the needs of the platform grew to require an upgrade to PostgreSQL — which has long been on my “learn this” list anyway. SQLite is very simple to set up and use, so I will be skipping that discovery and utility portion of the journey and instead solely discussing my endeavors with PostgreSQL.
I had to decide where I was going to host the platform and database. From the beginning, I knew that I was going to use Next.js for the frontend and I was going to create a server to store the database. So I deployed to a hardened Linux host with least-privilege access, network filtering, reverse proxying, and TLS — following standard hardening practices like SSH config, access-attempt monitoring with reactive banning; all that good stuff.
Next, I set up PostgreSQL (running as its own service) on that server. I decided to double-down on Python and use it for my DB’s architecture and API components with FastAPI as well as my scrapers, so I’ve gotten plenty of Python practice. The API runs under an ASGI server which itself is run under a process manager on the server for resilience and zero-touch restarts.
In a perfect world, I will be using TypeScript and Next.js for all of my frontend needs, Python for all of my data engineering and Machine Learning needs, and Rust for any low-level operations that I find myself building or indulging in.
I didn’t use Rust in this project, but I am using it in another. I liked it a lot when I was using it, but I’m getting Rusty not touching it in a while. — ʰᵃ

🖼️ The Frame and Glue (Schemas + FastAPI)
Now that I have a database established, I can now write some FastAPI endpoints to accept and send data — which I already made room and planned for ✌️ This part was relatively easy because it’s just connection and communication commands with SQL queries that I already had for my legacy SQLite database.
The main differences between SQLite and PostgreSQL are the environment variables required for PostgreSQL to find the database server process and authenticate access from the API that needed to be established (never hard-code sensitive information in your serious projects).
When using a “serious” PostgreSQL with Python, you should follow best practices regarding importing secrets and connection details. Be sure they are environment-isolated, not hard-coded, and loaded at runtime. That’s just good practice anyway, but we can get away with it sometimes for MVPs or casual SQLite DBs. Additionally, the way you input data into queries is a bit more strict in PostgreSQL relative to SQLite.
In PostgreSQL, the schema must match exactly for all requests, more guards should be in place for type safety and uniquity to prevent hiccups, all queries and commands must be 100% explicit, and all optional fields have to be labeled as optional. That’s great for a similar reason why TypeScript is generally better to use than JavaScript for “serious” projects; type safety and quality assurance of data. PostgreSQL does not interpret or guess anything, it runs how you tell it to with no deviations or exceptions — so we need to be specific in its configuration.
With scraper scripts now capable of scanning and pulling data from hundreds of stores dynamically and with somewhere to store the data reliably, the next step was to make the frontend so that I could pull the database data, render it, and interact with it.
I chose good ol’ Next.js because I’ve worked with it before, but also because I find that it suits my needs entirely without many external libraries. I generally prefer to write functionalities and features myself so that I can reasonably expect behaviors from my applications while also reducing bloat/footprint of the app. Between my custom code and built-ins, Next just does almost everything that I need it to do.

SQLite to PostgreSQL and JavaScript to TypeScript - time to put the gloves on.
🎨 The Paint (Next.js)
I’ve praised Next.js plenty in my articles and conversations with others. The file structure routing and API integration are so simple and convenient, and the navigation, link, image, useSearchParams, and other built-in Next modules are well documented, extremely useful, and cover almost all conventional cases that I would need a frontend to do. Using Next.js for frontend is something I will continue to do for the foreseeable future; easy decision.
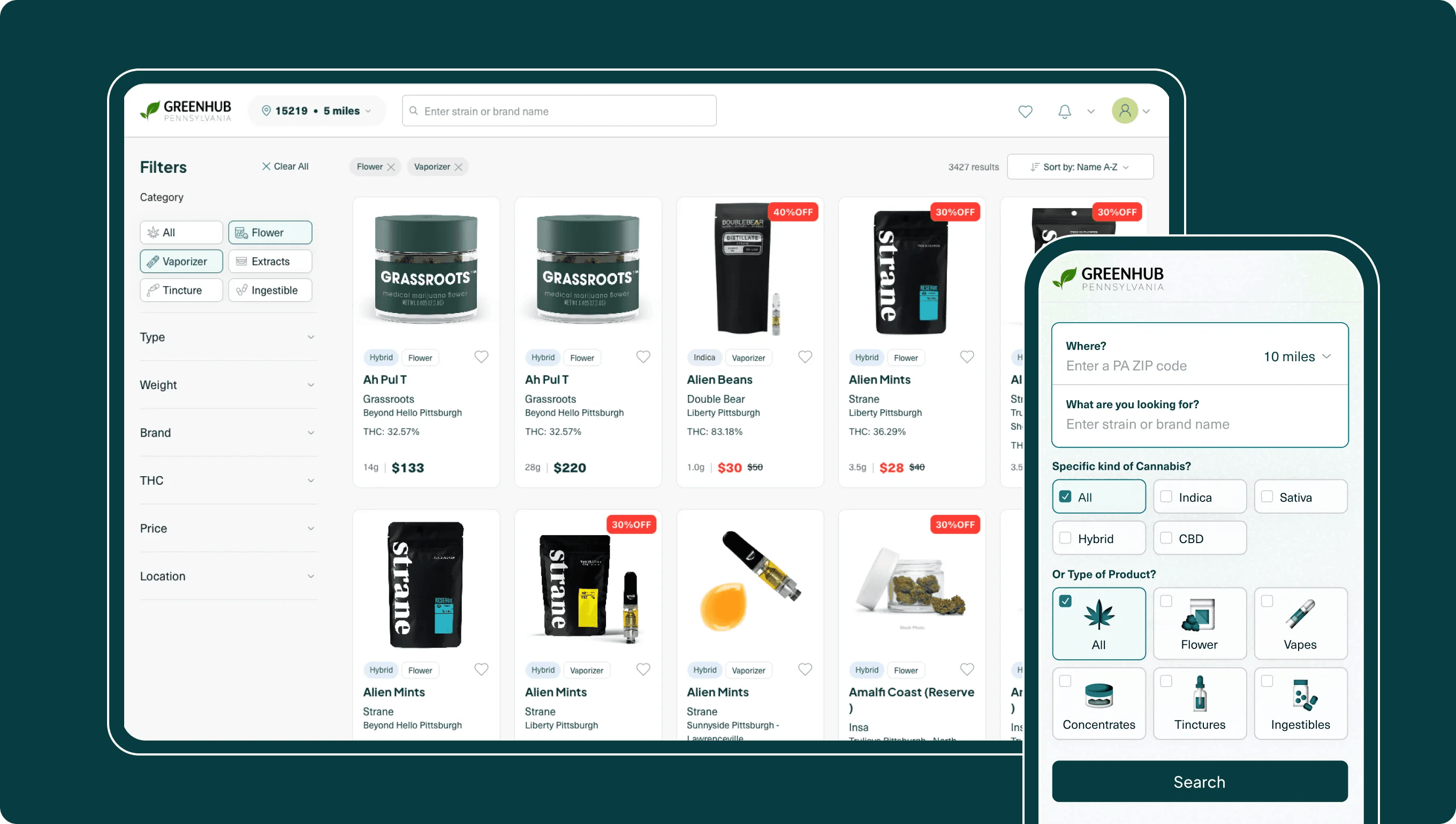
It was time to start working on the user experience flow. I took direct inspiration from the existing tool that prompted Greenhub’s creation — the platform would take a ZIP code and fetch all products within a given radius; simple in concept.
I looked into ways that I could make it easier for users by using cities instead of ZIP codes, but that would almost certainly in some way require me to use Google Maps and other dependency APIs that would cost us at scale. With ZIP codes, there is a free API geocoding service that I could use to input latitude and longitude coordinates and translate them to ZIP codes and vice versa. It’s not perfect — for example, the calculations that I use to determine distance will always use the center of the ZIP code’s total area, but it’s highly scalable, free, and accurate enough.
All stores will be tagged with a latitude and longitude — and all products are tied to a store. Therefore, I can use a “haversine” formula (standard formula to calculate radial distance) to calculate which stores are within a selected radial input to a selected ZIP code (which is also translated into geospatial coordinates) — then deliver all of the products to the user that are available in the stores that are within distance.

I very much considered how to deliver the data to the client — pagination, Snapshot the database daily and send a copy of the snapshot to the client, I even considered using SQLite on the frontend and using ISR/Revalidate daily to build the app with the new snapshot included after scraping so that it was immediately available — I liked that idea a lot.
In theory that would allow the snapshot to be accessed by a local instance of SQLite, reducing fetches through APIs, client and server load time, and making the browsing experience for users seamless, smooth, and extremely fast. I may implement this into the project later.
Building from that idea — and going a bit simpler — I decided to not host my Next.js frontend on Vercel (as I always have with Next.js projects) and instead I colocated critical services to reduce network hops and latency, which improved hop latencies, overall simplified ops after some configuration, and ultimately reduced server costs for me.
It’s probably not as fast to render as the snapshot architecture might be in theory, but it’s modular, easier to test, easier to maintain — and likely avoids premature micro-optimization. I’ll test snapshots one day just for funzies.
The main point is — removing Vercel from the loop — instead of;
- client → frontend server → database → frontend server → client
it now simply traverses from;
- client → server → client
Same payload size, but far less in-between total traffic — which reduced both complexity and cost in maintaining the server.

🪴 The Furnishings (Performance + Optimization)
I manually enabled compression on responses from the database for the client payload on my server config, which reduces the payload between 80-90% for JSON — which the deliverables always are — and therefore reducing load on client and again on my server responses. On my home network, I can receive ~25,000 products and complete first render in a little under 4 seconds; which is about the largest request a user can make in a metropolis area.
I really wanted the entire relevant dataset to be sent to the user, not in pages, and not in chunks. Chunks were not a viable option because the subsequent filtering for weights, types, categories, and such had to be done on the entire dataset to provide intact and full results. Pagination is standard, but I am fond of infinite scrolling and I strongly feel that it improves the user experience (as a user myself). So I decided against pagination also.
At this point for the frontend, we have ZIP code and radius inputs to request relevant items, and we get a compressed response from the database with normalized data. We catch that data and load it in an infinite-scroll list that renders a slice of results as an initial set, and incrementally batches additional items as the user scrolls. I implemented that with idiomatic React patterns and a touch of TailwindCSS so that it would load quickly and continue loading efficiently.

This technique allowed me to quickly render the first item into the DOM, provide infinite scrolling for the user, and access the entire dataset for filtering and sorting — all of which was a key part to the seamless and immersive user experience. I want users to forget they are interacting with a device, that is the hallmark of an excellent UX.
The sorting and filtering functionality was a lot of code for so many different filter options, but all-in-all it is very straightforward — apply a filter saying “if a product meets this condition, show it,” and multiple filters can be layered onto the dataset for fine control over searches.
I built the filter in O(n) time, as there will be a single pass through the dataset, collect the elements matching the current filter set into a new “toBeRendered” array, and then when the filter is complete it is shown to the user. This new array is a dependency for a useEffect, so if a filter is applied, the list reloads.
I briefly looked into running a web worker to offload the filtering and sorting so that the main thread wasn’t blocked, but at this stage of the project — when those operations are requested they are the only operation performing other than the rendering, which will happen after the filter/sort is finished anyway. Web workers for calculations like filtering are something that I have on the table as “to-dos” as the platform grows if I notice any drops in performance.
The next step was to optimize each card to render as fast as possible. I collect the images for each product from a CDN, so I have to fetch them from URLs that I’ve normalized and stored. Then I fetch the resource from that URL each item as the list renders, and almost all of them are PNGs or JPGs. Image optimization is almost always a huge area for performance improvements — specifically converting PNGs, JPGs, JPEGs, etcetera into WebP.
I built a custom conversion tool using Sharp — one of my favorite NPM libraries — to immediately convert the fetched image into a WebP on reception and before sending it to the client which are then cached. This dramatically reduced client payload and improved render times.
Finally, I memoized the Product card, so on subsequent filters and sorts the cards that have already rendered would load very quickly. The result is a sub 1 second filter/sorting action on up to 25,000 product cards at the largest radius I have available to search.

🔥📊 The Tools (Flame Charts + DevTools)
There were a few “aha!” moments that I had working with this project worth mentioning. The most prominent one was — there was a moment in development where the app was so fast and flowing perfectly together. I had a bad habit of working and building without committing every small change (working on correcting that behavior now), so suddenly after a few hours of working, I noticed that the app was crawling. I struggled for almost an entire day reading all of my code trying to make sense of where it could be slowing down because no dramatic changes were made.
Out of desperation, before I nuked my progress and rolled the codebase back, I started looking through all of the tooling in DevTools and saw the most obvious “Performance” that I have used 1000 times before to determine my LCP, and interaction timing with the pages; but there was a button I found there that I have never paid attention to — “record”.
I clicked the button, intuitively refreshed the page, ended the recording once the render completed, and a new chart that I have never seen before populated in the console; a flame chart. It shows every process, render, load, and element with their timing within the duration of the recording, and the information was beautiful. After looking through it for a few minutes trying to understand what I was looking at, it clicked.
I could see there was a useEffect call rendering the grid which had the product list as a dependency post filter and sort. I configured that intentionally so every time the filters changed, I could re-render the grid; standard stuff. However, I recently created a regex function to clean out a lot of the jank in some of the product names — like measurements, weights, brand name, etcetera.
Through the flame chart, I could see that the regex that I just introduced was cleaning the names of products in the sorted products dataset on render, but each and every individual name was cleaned would trigger additional renders of the product list. That would happen thousands of times until the all of the cards in the grid had clean product names through the regex. This annihilated my performance, taking the filter and sort from sub 1 second to 20+ seconds on a single filter action.

This is an optimized flame chart on a live production page reload at the time of writing.
Because of the chart, I was able to deduce the reason for the performance hit. I decided instead of keeping the regex on the frontend to clean the product cards as they render I should move it all to the backend. Then it would be done only once after scrapes, and I wouldn’t have to regex on every client for every render. In hindsight, I should have done that from the beginning. But hey, hindsight is 20/20. We live and learn.
I spent the day writing normalizers to take the what is now “source name” of a product on every scrape, which is the name that I receive for the product. Then, I can clean it through regex to a normalized “name” field, and pass that field with the dataset to the frontend to render. The performance was immediately and dramatically improved, and at that moment I felt like I added months to years of improvement to my craft with that one trick and toolset.
As for any additional optimization on the frontend with this new amazing analysis tool, I considered using virtualization with React Window over the infinite scroll for, but admittedly, the UI was already established precisely how it should be according to my designer’s system — so I decided to shelve the idea for later.
I’ll add virtualization in if I ever make an analytics page to look at all 120,000+ products simultaneously, if I ever notice a surge of users on very low-end or legacy devices complaining about render time, or if I ever feel like the extra work is deeply beneficial to the overall user-base; but at the moment the site is plenty fast, responsive, and great for what I and the majority of users need it to do.
🪵 The Maintenance (Logs + Monitoring)
Now being satisfied with how everything was working — and it was — it was time to optimize hot columns on tables (the fields hit most often in queries). I indexed the hottest of them, like the fields that are required to collect products based on ZIP code input or to correlate certain lists to users like the “saved products” list.
I also finalized the pipeline in such a way that I have a promotion process at the end of the main scraper script. To prevent downtime between scrapes, I insert all collected results from the current scrape into a temp table, and only when the scrape is done, I can:
- Archive the current live table into a historical table
- Drop the live table
- Rename the temp table to live table.
This also helps me in testing, because I can turn off the promotion process, run the scraper, get all the data sent to and held in the temp table, switch to dev URLs in a local env for DB fetches to routes that I made which pull the temp table data instead of the live data. With that I can do all kinds of data testing without impacting the normalized table for daily users.
After testing new scripts, schema changes, or pipeline updates, I can either:
- Run the promotion process, or
- Just drop the temp table and continue on business as usual.

The entire pipeline has extensive logging for individual scraper progress, insertion to db retries, fetch retries, store completion, store failures, total products gathered, total time taken, and more. It’s configured so that after each scrape I have a detailed report of what is working and what might need attention that day.
I also built some ancillary diagnostics scripts that request a single product from an API so that I know if I am able to safely run an operation, or if I have been flagged as a bad actor and to respectfully postpone the requests so that I do not interfere with business operations; theirs or mine.
To round-out the pipeline, I created quite a few API routes to handle basic calling actions like fetching data from and sending data to the PostgreSQL FastAPI component, fetching from external sources to GET rich data and PATCH to the database to store it for subsequent lookup requests, etc. That was really the last step — outside of securing all routes appropriately, the details of which I will willfully exclude as my secret sauce.
💅 The Adornments (UI/UX Design)
At this point of the project the MVP (Minimum Viable Product) was finished and my freelance agreement had long since been fulfilled. However, my client and I had seen much more potential for the project to grow. As patients ourselves, we knew that we were easing the pain-points for patients and users to find the medicine that they were looking for, and there was a lot more we wanted to do.
We decided to start an LLC in which we were both equal founders to give the platform the love and attention that it deserves so that it had the chance to thrive in a way that we believed it could. So now I have the pleasure in experiencing the role of founding full-stack engineer for a startup as what is technically on legal documents as CTO. Isn’t that something.
Anyway, before I start another rant about the broken job market and hiring practices — we brought on my favorite UI/UX designer to overhaul the existing layout that I managed to piece together, including custom illustrations, layouts, logos, flows, and such. She is an exceptional UI/UX/Product designer, and I’ve been very lucky to have incorporated her work into almost all of my projects. As a specialist, she saw possibilities that neither my co-founder nor I would have considered.
The redesign made the platform far more intuitive and enjoyable to use. I credit it as one of the key drivers behind our sudden and rapid user growth — changing reactions from “this is a pretty neat tool” to “wow, this is amazing.”
🌹 Special thanks to Yuu Ito, the Co-Founder and designer of the Tsundoku platform!
If you like her work, check out Her Portfolio and Her LinkedIn.

🏡 Open House! (Adding User Accounts and Features)
My first action as the esteemed CTO (lol) was to add the option to register accounts which are secured with Bcrypt password salted hash, and authenticated with JWT distribution and validation server side.
Next, I built a feature allowing users to save products they were interested in or knew they liked, so they could revisit them later. From there, I added a backend process to track and calculate price deltas by comparing each user’s saved items to the daily scrape of available products.
This allowed me to request updated info on demand (once per day when a user signs in or interacts with the app) from all of the products that a user saved. The comparison detects price changes from one non-zero integer to another, or from zero to a non-zero integer, and flags these changes to trigger notifications: price drops and restocks, delivered automatically. Voilà — live product updates and daily notifications.
At the time of writing, Greenhub is an active LLC in Pennsylvania, serving thousands of users and patients by helping them find medicine at convenient locations. Our roadmap includes more conveniences and features — always with a focus on making the shopping experience easier and better for patients. It’s a sector of the industry we believe is still underrepresented.

☀️ Summary
Greenhub is the largest, most comprehensive, broadly spanning project that I have had the pleasure to work on. It wasn’t long ago that I thought building a platform with 25 daily users was an amazing feat. Now, we have up to 150 unique users a day with an average visit duration of between 5 to 7 minutes.
We launched our alpha a little over a month ago and we have attracted 3,500+ unique users,— most of which are now recurring — amassed 7,000 visits, and hosted 30,300 page views. I’ve made quite a complicated system as you can see below.

Claude Opus made this. It's not perfect, but I think he did a pretty good job 🙂
The goal was simple: help patients find the right product faster with ease. Today, thousands of patients in Pennsylvania do — without juggling tabs or guesswork. I’m excited to keep sharpening and widening the data and user experience so that finding medicine for depression, anxiety, pain, appetite loss, or any of the many ailments users soothe with cannabis is as easy as it always should have been.
If you are a medicinal cannabis patient in PA, know someone who is a patient and care to help them, or just have an interest in the industry (and are over 21 😉) then check out or share the platform; you are the target audience. If you want to talk shop, I’m always up for a coffee chat about code and system design.
We have so much more planned for Greenhub, this is only the beginning. To our current users — thank you 🙂 To new readers and future users — thank you 😀 And to those who may never use the platform but still read this whole article — thank you as well 🤭 Take care!

Steven
Guide Me to Shore: Lighthouse Refactor Case Study - Tsundoku
A case study on maximizing web performance of a Next.js application through media reformatting, hybrid rendering strategies, and building local fonts
Steven
Content Management with Sanity: From ‘A Studio’ to ‘A Nice Studio’
How and why I customized my Sanity Studio—adding a preview pane, dynamic slug routing, SSR cookie-based session handling, and API routes to improve content editing.
Steven
From Curious to Coding 2: Building a Blog with Next.js, Sanity, TypeScript, and Tailwind
A detailed account of the development of this blog, what I learned, and what I used to build it.